As a sysadmin, one of the “rainy day” things on my to-do list for some time has been exploring centralized logging. I’ve done a few proof of concept style quick implementations throughout the years but have never been able to secure budget or resources to see it to completion. Splunk was too expensive, and the open source ones I tried required too much effort to be worth while back then. This time, however, I was more determined to make something stick. With that, I began searching out some of the more popular open source tools.
I considered various combinations of things like Fluentd, Graylog2, Octopussy, etc. In the end, I settled on going with the Logstash/Elasticsearch/Kibana stack. All of these free, open source tools are powerful in their own right – but they’re designed to work together and are immensely powerful when combined. Logstash collects, ships, filters, and makes logs consistent. Elasticsearch creates indices and searchability of the logs. And finally, Kibana gives you a great web interface to analyze all your log data. Here’s a screenshot of it all coming together for me. This is a custom Kibana dashboard showing syslog output from all my VMware servers:
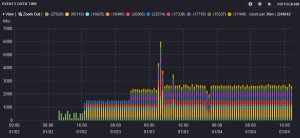
Before diving into the steps, I feel the need to point out that I’ve had a great time learning and setting up these tools. I honestly haven’t been this excited about using software since first trying VMware ESX server. I can’t stop working on it. It’s become an addiction for me to continuously improve, filter, and make sense of various logs. It’s really very rewarding to be able to visualize your log data in such a usable way. Everything was pretty easy to set up at a basic level, and the open source community was there for me via #logstash on IRC when I needed help taking things further or had any questions. The setup of these tools can feel a little daunting to a newcomer with so many options and such a degree of configurability/customization, so I wanted to provide a step-by-step guide for how I ended up with an initial deployment.
A couple prerequisite disclaimer points before I get started
- I chose to use Ubuntu server. This is a personal preference, and certainly this guide can be helpful if you choose a different OS. Use whatever OS you feel comfortable with.
- For the purposes of this guide, all 3 tools will be run on one server. It is possible (even recommended depending on your workload) to separate them onto different servers.
- This is a “getting started” guide. These tools can certainly be taken much further than I take them here. They can be integrated with a message broker like Redis or RabbitMQ. I’ll consider going into deeper options such as these in a followup enhanced configuration guide vs. here in the getting started guide.
Now let’s get into the setup!
- Get a webserver and PHP installed on your server. I much prefer apache or nginx as the webserver. Logstash does has a built in webserver that you can run, but I much prefer running a separate webserver. In Ubuntu, I just went with the entire LAMP stack. This is as easy as “apt-get install lamp-server“.
- Install a java runtime. Again, easy in Ubuntu via apt-get install openjdk-7-jre-headless
- Download the three components. I downloaded gzip archives of each, but depending on your OS, there may be packages built for it. Choose whichever way you’re more comfortable with.
- Extract the archives (tar -xvf <filename>.tgz) and place the files where you want them. I chose /opt for logstash and elasticsearch, and then Kibana goes in your web root. I did it as follows, an;d I’ll continue to reference these directories in the rest of the guide.
- Extracted Elasticsearch tgz to /opt/elasticsearch
- Placed the Logstash jar in /opt/logstash
- Extracted Kibana tgz to my web root folder, /var/www/kibana – there was no special configuration needed other than putting the files here.
- Edit your Elasticsearch config file (/opt/elasticsearch/config/elasticsearch.yml) and make 2 edits:
- Find the line that says “cluster.name” and uncomment it, setting a name for your new Elasticsearch cluster.
- Look for “node.name” and set the node name as well.
- Note that you don’t have to set these variables. If you don’t set these, Elasticsearch will set them randomly for you, but it is handy to know which server you’re looking at if you ever have to expand your setup so I recommend setting them.
- Go ahead and start Elasticsearch by running /opt/elasticsearch/bin/elasticsearch
- Create a basic logstash.conf file. I created an /opt/logstash/logstash.conf with an initial config something like this, which just creates local file inputs.
input {
file {
type => "linux-syslog"
path => [ "/var/log/*.log", "/var/log/messages", "/var/log/syslog" ]
}
}
output {
stdout { }
elasticsearch { cluster => "YourclusterName" }
}
This input section is defined to look at and ingest files defined in the path array variable. Then the output section is setting to output to stdout (your command window) and also to elasticsearch where you define your cluster name. This is a very basic config to easily show us things are working.
- Now fire up Logstash by running: /opt/logstash/bin/logstash agent -f /opt/logstash/logstash.conf
- You should now see logstash initialize and all of the events it indexes should get output to your terminal via the stdout output, in addition to getting pushed over to elasticsearch where we should see them with Kibana.
- If you extracted Kibana as noted in step 4, then you should be able to browse to your server and check out your data! Try http://yourserver/kibana and you should be greeted with an introduction screen. You’ll see they have a pre-configured logstash dashboard that you can click on and save as your default
- Once you see your data is indeed visible through Kibana, we can dive into further configuration of logstash. If something’s off and you don’t see data, check out the logstash docs or jump into #logstash on irc.freenode.net where people are very happy to help. Once you’re satisfied that it is working, you may want to remove the stdout line from the output section and only have your output go to Elasticsearch for indexing.
- Now that we know things are functional, we can set up some additional logstash configs to further improve things
- Now we’re ready to have some servers to dump syslogs to your new central log server! I started with VMware and Ubuntu and branched out from there. Depending on your OS or the syslog implementation, the method of sending logs to a remote syslog host varies. Check your OS documentation for how to do this. The default port is 514, which is default for the syslog input and typically remote hosts sending syslog data.
- Check out Kibana now and hopefully you see log entries. Click through on hosts, on tags, try creating a new dashboard displaying only your “VMware” tagged logs. Etc Etc Etc – hopefully you can see your filters in action and how it helps bring consistency to your log data.
- Keep exploring the Logstash docs for more inputs. Windows servers, Cisco devices, apache or IIS logs, Exchange, etc. I don’t think there’s a sysadmin out there who has a shortage of log data they could/should be analyzing.
- Document your setup as you go so you can remember it later. 🙂
I hope this startup guide has been helpful to getting a base configuration. Keep in mind that Logstash has a plethora of inputs, outputs codecs and filters. Make sure to check out all the documentation at http://logstash.net/docs/1.3.2/ and tailor this awesome tool to your needs. If you have a system logging, chances are there’s an input or plugin for it.
A few bonus tips
- Check out http://www.elasticsearch.org/videos/, particularly “Introduction to Logstash”
- Install a few awesome plugins for Elasticsearch
- /opt/elasticsearch/bin/plugin -install karmi/elasticsearch-paramedic
- /opt/elasticsearch/bin/plugin -install royrusso/elasticsearch-HQ
- /opt/elasticsearch/bin/plugin -install mobz/elasticsearch-head
- Move your logstash dashboard to default by browsing to /var/www/kibana/app/dashboards and copying logstash.json to default.json. Maybe save default.json off as default.json.orig or something first.
- Make sure to visit the Logstash community cookbook.



{kind=link}