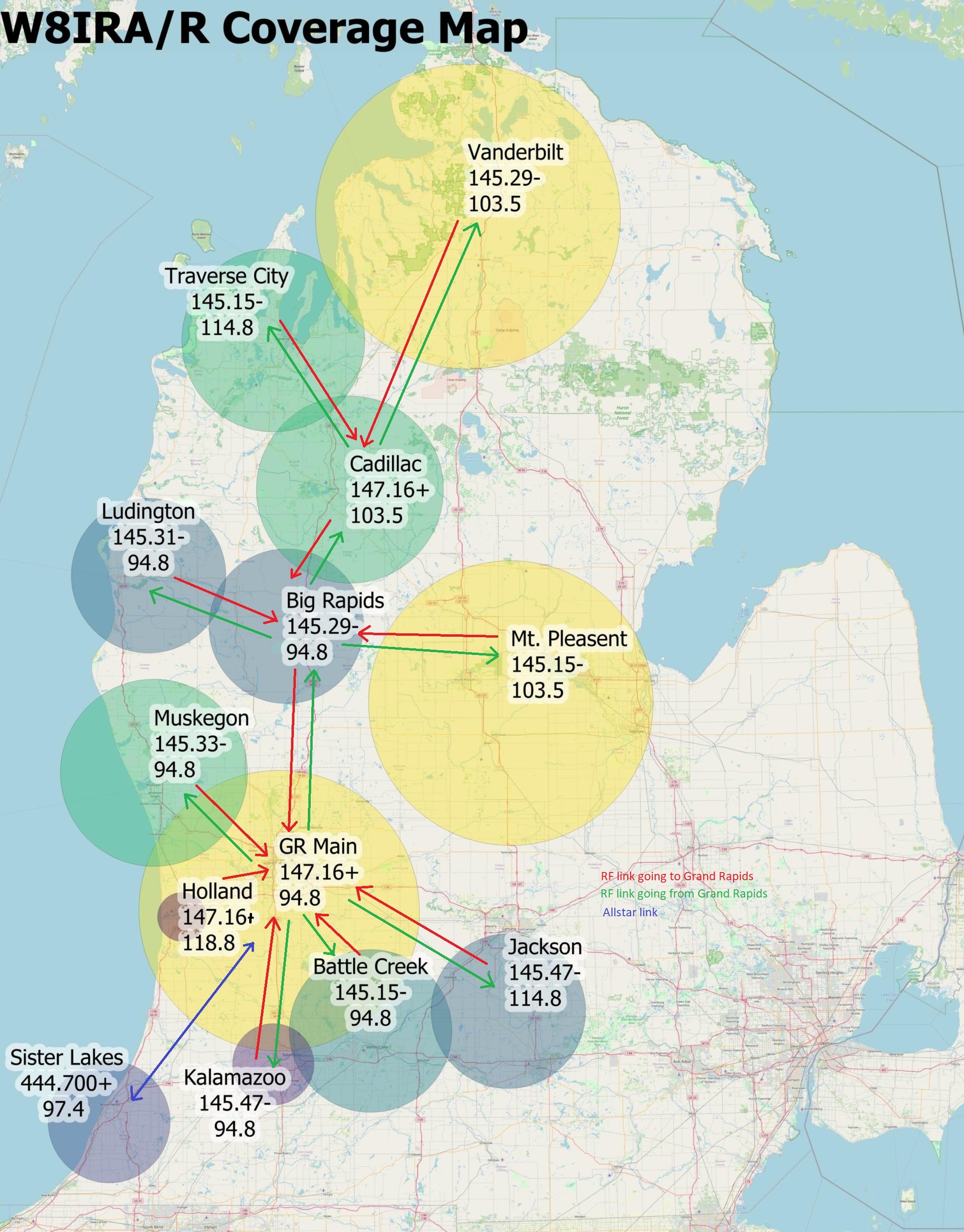
Originally Posted: November 9, 2009
(1:09:53 PM) working vanlandw: VANBERGE
(1:10:31 PM) vanberge4: yo
(1:10:38 PM) working vanlandw: do you know if staying at the inn restores your hp?
(1:11:13 PM) vanberge4: i do not know actually
(1:11:25 PM) working vanlandw: this game is bullshit everybody is ahead of me there is nothing i can do everybody obove me is just going ot keep poaching me
(1:13:57 PM) vanberge4: actually i htink you’re ok now
(1:14:05 PM) vanberge4: people can only attack you if they are at your level or 1 higher
(1:14:09 PM) vanberge4: 2+ and it fails
(1:15:38 PM) vanberge4: you should slay flo and payner in their respective inns
(1:15:43 PM) vanberge4: you can use death knight attacks
(1:15:48 PM) working vanlandw: tomorrow
(1:15:50 PM) vanberge4: nope
(1:15:51 PM) vanberge4: NOW
(1:15:55 PM) working vanlandw: i should have enough money ot buy the next armor upgrade
(1:16:00 PM) working vanlandw: then i’ll have the 30,000 upgrades
(1:16:03 PM) working vanlandw: then i should have a chance
(1:16:27 PM) vanberge4: you should try vanlandw! you can do it!
(1:16:36 PM) vanberge4: if you kill them you’ll get some G
(1:16:47 PM) working vanlandw: i’m not strong enough
(1:16:54 PM) working vanlandw: i tried killing flo
(1:16:54 PM) vanberge4: dude it doesnt matter with DK attacks
(1:17:01 PM) working vanlandw: it didn’t work
(1:17:02 PM) vanberge4: i hit jja for 600 damage when i was a level 7
(1:17:08 PM) working vanlandw: tomorrow
(1:17:17 PM) working vanlandw: right now i’m just going to bide my time till i have enough dough to upgrade
(1:17:26 PM) working vanlandw: then i’ll upgrade and i should have enough money tot ake out flo or payner
(1:17:30 PM) working vanlandw: hopefully lol
(1:18:24 PM) vanberge4: do you have hte long sword ?
(1:18:27 PM) vanberge4: or the “huge axe”
(1:19:15 PM) vanberge4: ** YOU ARE STOPPED BY A MESSENGER WITH THE FOLLOWING NEWS: **
Vanlandw has left the realm.
(1:19:29 PM) working vanlandw: i got idle
(1:19:32 PM) working vanlandw: i’m on the phone
(1:19:44 PM) working vanlandw: are you going to murder me in the field?
(1:19:45 PM) vanberge4: I am going to transfer you 60,000 dollars to get your upgrades and fight flo. You have had a bad start and I want to help you
(1:19:50 PM) working vanlandw: LOL
(1:19:55 PM) vanberge4: if you say no, then I’m going to murder you
(1:20:03 PM) working vanlandw: do you have enough funds?
(1:20:09 PM) vanberge4: yeah i have like 300k in the bank
(1:20:11 PM) working vanlandw: you have already lent me a series of dollars
(1:20:18 PM) working vanlandw: i don’t know if ic an beat them
(1:20:23 PM) working vanlandw: i have the axe
(1:20:44 PM) vanberge4: you’re going to try
(1:20:50 PM) vanberge4: use your D attack
(1:20:54 PM) vanberge4: it’ll be a gg
(1:21:00 PM) working vanlandw: lmao
(1:21:03 PM) working vanlandw: that would be pretty funny
(1:21:08 PM) working vanlandw: i don’t know if i have more then one d attack
(1:21:30 PM) working vanlandw: i have 3 “Death knight skills”
(1:21:34 PM) vanberge4: vanlandw you have to take a chance
(1:21:41 PM) working vanlandw: i guess i have to
(1:21:42 PM) vanberge4: i started off really crappy
(1:21:50 PM) working vanlandw: i started out really crappy
(1:21:50 PM) vanberge4: but I killed kramer when he was at the top
(1:21:56 PM) vanberge4: using my D attack
(1:22:03 PM) vanberge4: it was a great risk but well worth it
(1:22:18 PM) working vanlandw: you are now number one
(1:22:26 PM) vanberge4: yup
(1:22:27 PM) working vanlandw: and vo is not doing very well
(1:22:31 PM) working vanlandw: he died int eh field today
(1:22:33 PM) vanberge4: because i fight people who are ahead of me
(1:22:52 PM) vanberge4: i slayed jja yesterday and he was way above me in exp
(1:23:00 PM) vanberge4: it’s all in the “D”
(1:23:27 PM) vanberge4: it said it transferrred the money but I dont see any of it
(1:23:34 PM) vanberge4: see if you have it
(1:23:43 PM) working vanlandw: ok i will
(1:25:35 PM) vanberge4: how much would you need for a way higher weapon ?
(1:26:15 PM) working vanlandw: 100,000
(1:27:07 PM) vanberge4: what armor do you have
(1:27:27 PM) working vanlandw: leather
(1:27:32 PM) working vanlandw: i was saving for the next one at 30,000
(1:27:49 PM) vanberge4: buy the iron armour
(1:28:01 PM) vanberge4: actually im going to give you more money so you can upgrade both of these
(1:28:07 PM) vanberge4: i want to make sure you can kill flo
(1:29:01 PM) vanberge4: i have sent you 200,000
(1:29:07 PM) vanberge4: buy good shit; kill flo and payner
(1:31:12 PM) working vanlandw: wow
(1:31:15 PM) working vanlandw: that is so funny
(1:31:54 PM) vanberge4: i am helping a fellow van who has had a rough go of it
(1:32:01 PM) vanberge4: i make like 30k per forest fight so iz gg
(1:35:14 PM) vanberge4: you HAVE to try fighting them now.
(1:35:16 PM) vanberge4: ![]()
(1:35:26 PM) working vanlandw: i’m workin on it
(1:35:32 PM) vanberge4: if you still say “tomorrow” im going to go in administratively and take that money away and make your guy dead
(1:35:38 PM) working vanlandw: no i’m going to
(1:35:43 PM) working vanlandw: i just gotta do a few work things
(1:35:43 PM) vanberge4: =D
(1:35:59 PM) vanberge4: i love you vanlandw
(1:36:11 PM) vanberge4: harness the engergy of lendale white and ricky williams to help you through it
(1:37:37 PM) working vanlandw: i wonder if i’m not high enough level to buy that equpiment
(1:38:11 PM) vanberge4: it shouldtn matter
(1:39:17 PM) working vanlandw: i have the bone cruncher and graphite armour
(1:39:20 PM) vanberge4: amazing
(1:39:46 PM) working vanlandw: seriously he’s going to kill me
(1:39:53 PM) vanberge4: D
(1:40:01 PM) working vanlandw: Being a trained warrior, he jumps up suddenly, aware of your
presence!
**PLAYER FIGHT**
You have encountered E-Flo!!
E-Flo surprises you.
** E-Flo Executes A Power Move **
** E-Flo hits with his Bone Cruncher for 66 damage! **
Your Hitpoints : 1
E-Flo’s Hitpoints : 149
(1:40:10 PM) working vanlandw: You have killed E-Flo!
(1:40:11 PM) vanberge4: Run and try again
(1:40:13 PM) vanberge4: LOL
(1:40:17 PM) vanberge4: you did it!!!
(1:40:20 PM) working vanlandw: i am lmfao
(1:40:29 PM) vanberge4: this has been an amazing thing
(1:40:45 PM) vanberge4: you literally had 1 point
(1:40:59 PM) vanberge4: that is just awesome
(1:41:00 PM) working vanlandw: i don’t know if i can take payner
(1:41:10 PM) working vanlandw: if flo pretty much murdered me i don’t think i can get him
(1:41:21 PM) working vanlandw: i guess i can try
(1:41:21 PM) vanberge4: do you have more D
(1:41:35 PM) vanberge4: you didnt get uch xp for that… i’m surprised
(1:41:43 PM) working vanlandw: nope no more d
(1:42:04 PM) vanberge4: you prob can level up
(1:42:07 PM) working vanlandw: nope
(1:42:09 PM) vanberge4: then you might get a new D
(1:42:10 PM) working vanlandw: i’m going to stay here
(1:42:19 PM) working vanlandw: at 4 nobody can kill me lol
(1:42:23 PM) vanberge4: VANLANDW
(1:42:26 PM) working vanlandw: i’ll prob kill flo and payner for a few days
(1:42:29 PM) working vanlandw: then wait to level up
(1:42:36 PM) working vanlandw: payner and flo are 6
(1:42:38 PM) working vanlandw: they can’t kill me
(1:42:44 PM) working vanlandw: i pretty much rather just piss them off
(1:42:56 PM) vanberge4: if you visit turgon does he say” ooh your muscles are big like lendale”
(1:43:10 PM) working vanlandw: lol yeah he does
(1:43:12 PM) vanberge4: that will refresh your D and you can take out payner!
(1:43:17 PM) working vanlandw: hmmm
(1:43:25 PM) working vanlandw: does that give you “D” leveling up?
(1:43:28 PM) vanberge4: vanlandw this is just an epic day
(1:43:30 PM) working vanlandw: lol
(1:43:31 PM) vanberge4: i think it does!
(1:43:39 PM) vanberge4: you can kill them both!
(1:43:42 PM) vanberge4: COME ON
(1:43:46 PM) vanberge4: you have to try!!!! :-/
(1:43:50 PM) working vanlandw: “You’re becoming a very skilled warrior.”
(1:43:54 PM) vanberge4: dude
(1:43:59 PM) vanberge4: heal your guy first tho
(1:44:08 PM) working vanlandw: Ye Gods!! You are a master warrior!
(1:44:29 PM) working vanlandw: i do have another use lol
(1:44:34 PM) working vanlandw: ok i’ll try to get payner
(1:44:36 PM) vanberge4: yes
(1:44:38 PM) vanberge4: you will
(1:44:39 PM) vanberge4: lol
(1:44:42 PM) vanberge4: this is so awesome
(1:45:14 PM) working vanlandw: You hit Payner for 179 damage!
You blew your master away!
You have killed Payner!
(1:45:19 PM) working vanlandw: lol?
(1:45:20 PM) vanberge4: wow
(1:45:23 PM) vanberge4: this is just amazing
(1:46:52 PM) working vanlandw: i have reutrned to the mundane world
(1:46:57 PM) vanberge4: man
(1:46:57 PM) working vanlandw: i just murdered everybody
(1:47:00 PM) vanberge4: what an epic day
(1:47:04 PM) working vanlandw: they must be so pist
(1:47:05 PM) vanberge4: that was seriously awesome vanlandw
(1:47:29 PM) vanberge4: now see what that did? you went from lik 2,000 xp to 27k
(1:47:33 PM) vanberge4: you’re right in the mix
(1:47:52 PM) working vanlandw: well without any help i would be getting my shit pushed
(1:48:38 PM) vanberge4: how awesome was that though
(1:48:51 PM) vanberge4: we have just conspired to the nth degree and committed sheer LoRD espionage warfare
(1:48:51 PM) working vanlandw: they are going to be so pist lol
(1:49:09 PM) vanberge4: i am posting this entire chat on my website
(1:49:10 PM) vanberge4: lol
(1:49:30 PM) working vanlandw: getting sold out is so funny